Hello and welcome to my research page. My name is Serban (pronounced Sir-Bon) Porumbescu (pronounced Pour-oom-bess-coo).
I completed my PhD in 2005. During my studies, my research was primarily focused on 2D
surface parameterization and remeshing of large data.
Some of my most interesting results involve 3D near surface parameterizations
(see Shell Maps below). Ken Joy was my advisor.
After graduating in 2005, I spent some time at Sony R&D, NVIDIA, and my own little startup that focused on work in the nonprofit sector. In October 2008 I started a new company, Hidden Elephant, focused on iPhone application development.
I joined iPhone startup Tapulous in
October of 2009 as a senior gameplay engineer. While there I worked on a
number of different projects (two that come to mind: Tap Tap Radiation and
Riddim Ribbon). That Fall I also designed and taught UCD's first iPhone development
course with Ken Joy.
I left Tapulous in September of 2010, two months after we were acquired by Disney, to focus on my own indie development projects.
In November 2010 my company, Hidden Elephant, partnered with Limbic Software.
Together we developed the hit iOS game, Zombie Gunship (released July, 2011).
I spent the rest of 2011 and big chunks of 2012 adding features and updating Zombie Gunship.
I launched Lexmee, a puzzle word game, for iOS
February 28th, 2013.
May 8th, 2014 Gunship X, a top down shooter for iOS, is released.
Nov 19th, 2014 announced Gunship X for PS4 and PS Vita (trailer here).
Oct 6th, 2016 Brett Red and I presented "The Future of Sharing Ideas" at TEDx San Francisco. You can see the video on YouTube.
May 15th, 2018 released Sculptura, a high-resolution voxel sculpting application for iOS and macOS.
September, 2018 I sold off my interst in Sculptura.
October 20th, 2018 I joined John Owens' amazing GPU computing group at UC Davis as a Postdoctoral Scholar.
You can reach me via email at idav 'at' hiddenelephant.com.
Checkout Google Scholar for an updated list of publications.
A Programming Model for GPU Load Balancing.
Muhammad Osama, Serban D. Porumbescu, and John D. Owens.
In Proceedings of the 28th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPoPP 2023, February/March 2023.
We propose a GPU fine-grained load-balancing abstraction that decouples load balancing from work processing and aims to support both static and dynamic schedules with a programmable interface to implement new load-balancing schedules. Prior to our work, the only way to unleash the GPU's potential on irregular problems has been to workload-balance through application-specific, tightly coupled load-balancing techniques.
With our open-source framework for load-balancing, we hope to improve programmers' productivity when developing irregular-parallel algorithms on the GPU, and also improve the overall performance characteristics for such applications by allowing a quick path to experimentation with a variety of existing load-balancing techniques. Consequently, we also hope that by separating the concerns of load-balancing from work processing within our abstraction, managing and extending existing code to future architectures becomes easier.
Muhammad A. Awad, Saman Ashkiani, Serban D. Porumbescu, Martín Farach-Colton, and John D. Owens.
In SIAM Symposium on Algorithmic Principles of Computer Systems, APOCS23, January 2023.
We revisit the problem of building static hash tables on the GPU and present an efficient implementation of bucketed hash tables. By decoupling the probing scheme from the hash table in-memory representation, we offer an implementation where the number of probes and the bucket size are the only factors limiting performance. Our analysis sweeps through the hash table parameter space for two probing schemes: cuckoo and iceberg hashing. We show that a bucketed cuckoo hash table (BCHT) that uses three hash functions outperforms alternative methods that use iceberg hashing and a cuckoo hash table that uses a bucket size of one. At load factors as high as 0.99, BCHT enjoys an average probe count of 1.43 during insertion. Using three hash functions only, positive and negative queries require at most 1.39 and 2.8 average probes per key, respectively.
Muhammad A. Awad, Serban D. Porumbescu, and John D. Owens.
In Proceedings of the International Conference on Parallel
Architectures and Compilation Techniques, PACT 2022, October 2022.
We introduce a GPU B-Tree that supports snapshots and offers updates, point queries, and linearizable multipoint queries. The supported operations can be performed in a phase-concurrent, asynchronous, or fully-concurrent fashion. Our B-Tree uses cache-line-sized nodes linked together to form a version list and a GPU epoch-based reclamation scheme to reclaim older nodes' versions safely. Our data structure supports snapshots with minimal overhead in point queries (1.04X slower) and insertions (1.11X slower) versus a B-Tree that does not support versioning. Our linearizable B-Tree performs similarly to the non-linearizable baseline for read-heavy workloads and 2.39X slower for write-heavy workloads when performing concurrent range queries and insertions. In addition, we introduce different GPU-aware snapshot scopes that allow the use of our data structure for phase-concurrent (synchronous), stream-concurrent (asynchronous), and on-device fully-concurrent operations.
Atos: A Task-Parallel GPU Dynamic Scheduling Framework for Dynamic Irregular Computations
Yuxin Chen, Benjamin Brock, Serban Porumbescu, Aydin Buluc, Katherine Yelick, and John D. Owens.
ICPP 2022
We present Atos, a task-parallel GPU dynamic scheduling framework that is especially suited to dynamic irregular applications. Compared to the dominant Bulk Synchronous Parallel (BSP) frameworks, Atos exposes additional concurrency by supporting task-parallel formulations of applications with relaxed dependencies, achieving higher GPU utilization, which is particularly significant for problems with concurrency bottlenecks. Atos also offers implicit task-parallel load balancing in addition to data-parallel load balancing, providing users the flexibility to balance between them to achieve optimal performance. Finally, Atos allows users to adapt to different use cases by controlling the kernel strategy and task-parallel granularity. We demonstrate that each of these controls is important in practice. We evaluate and analyze the performance of Atos vs. BSP on three applications: breadth-first search, PageRank, and graph coloring. Atos implementations achieve geomean speedups of 3.44x, 2.1x, and 2.77x and peak speedups of 12.8x, 3.2x, and 9.08x across three case studies, compared to a state-of-the-art BSP GPU implementation. Beyond simply quantifying the speedup, we extensively analyze the reasons behind each speedup. This deeper understanding allows us to derive general guidelines for how to select the optimal Atos configuration for different applications. Finally, our analysis provides insights for future dynamic scheduling framework designs.
Supporting Unified Shader Specialization by Co-opting C++ Features
Kerry A. Seitz, Jr., Theresa Foley, Serban D. Porumbescu, and John D. Owens.
Proceedings of the ACM on Computer Graphics and Interactive Techniques 2022
Modern unified programming models (such as CUDA and SYCL) that combine host (CPU) code and GPU code into the same programming language, same file, and same lexical scope lack adequate support for GPU code specialization, which is a key optimization in real-time graphics. Furthermore, current methods used to implement specialization do not translate to a unified environment. In this paper, we create a unified shader programming environment in C++ that provides first-class support for specialization by co-opting C++'s attribute and virtual function features and reimplementing them with alternate semantics to express the services required. By co-opting existing features, we enable programmers to use familiar C++ programming techniques to write host and GPU code together, while still achieving efficient generated C++ and HLSL code via our source-to-source translator.
Muhammad Osama, Serban D. Porumbescu, and John D. Owens.
In Proceedings of the Workshop on Graphs, Architectures, Programming, and Learning, GrAPL 2022, pages 314–317, May 2022.
We identify the graph data structure, frontiers, operators, an iterative loop structure, and convergence conditions as essential components
of graph analytics systems based on the native-graph approach. Using these essential components, we propose an abstraction that captures
all the significant programming models within graph analytics, such as bulk-synchronous, asynchronous, shared-memory, message-passing,
and push vs. pull traversals. Finally, we demonstrate the powerof our abstraction with an elegant modern C++ implementationof single-source
shortest path and its required components.
Muhammad A. Awad, Saman Ashkiani, Serban D. Porumbescu, Mart�n Farach-Colton, and John D. Owens.
CoRR, abs/2109.14682(2109.14682v1), September 2021.
We revisit the problem of building static hash tables on the GPU and design and build three bucketed hash tables that use different probing schemes. Our implementations are lock-free and offer efficient memory access patterns; thus, only the probing scheme is the factor affecting the performance of the hash table's different operations. Our results show that a bucketed cuckoo hash table that uses three hash functions (BCHT) outperforms alternative methods that use power-of-two choices, iceberg hashing, and a cuckoo hash table that uses a bucket size one. At high load factors as high as 0.99, BCHT enjoys an average probe count of 1.43 during insertion. Using three hash functions only, positive and negative queries require at most 1.39 and 2.8 average probes per key, respectively.
Ahmed H. Mahmoud,
Serban D. Porumbescu,
John D. Owens
ACM SIGGRAPH 2021
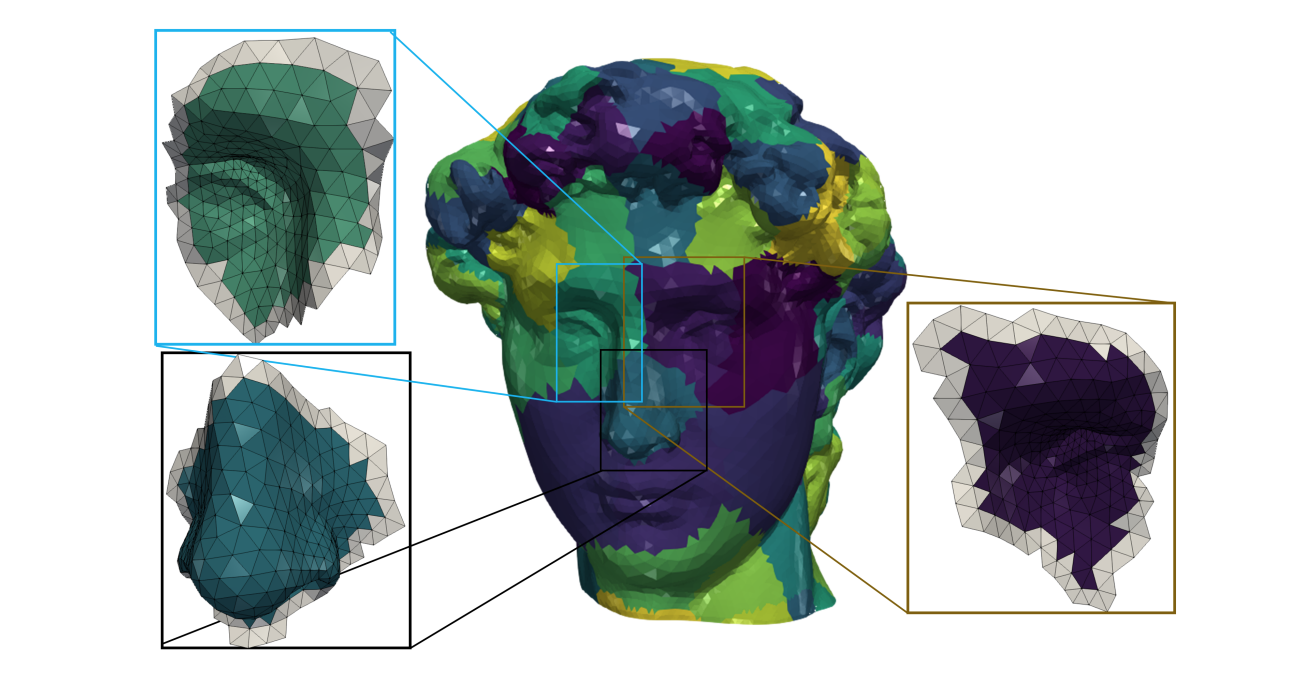
We propose a new static high-performance mesh data structure for triangle surface meshes on the GPU. Our data structure is carefully designed for parallel execution while capturing mesh locality and confining data access, as much as possible, within the GPU's fast shared memory. We achieve this by subdividing the mesh into patches and representing these patches compactly using a matrix-based representation. Our patching technique is decorated with ribbons, thin mesh strips around patches that eliminate the need to communicate between different computation thread blocks, resulting in consistent high throughput. We call our data structure RXMesh: Ribbon-matriX Mesh. We hide the complexity of our data structure behind a flexible but powerful programming model that helps deliver high performance by inducing load balance even in highly irregular input meshes. We show the efficacy of our programming model on common geometry processing applications: mesh smoothing and filtering, geodesic distance, and vertex normal computation. For evaluation, we benchmark our data structure against well-optimized GPU and (single and multi-core) CPU data structures and show significant speedups.
Muhammad A. Awad,
Saman Ashkiani,
Serban D. Porumbescu,
John D. Owens
IPDPS 2020
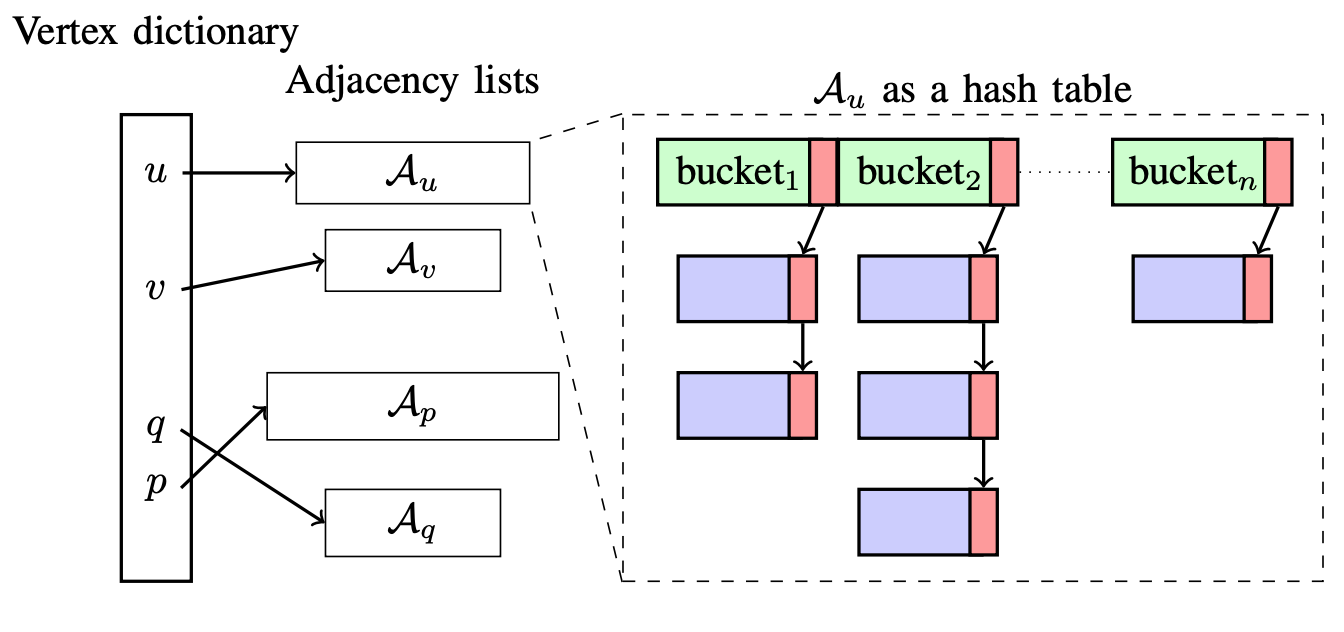
We present a fast dynamic graph data structure for the GPU. Our dynamic graph structure uses one hash table per vertex to store adjacency lists and achieves 3.4 to 14.8x faster insertion rates over the state of the art across a diverse set of large datasets, as well as deletion speedups up to 7.8x. The data structure supports queries and dynamic updates through both edge and vertex insertion and deletion. In addition, we define a comprehensive evaluation strategy based on operations, workloads, and applications that we believe better characterize and evaluate dynamic graph data structures.
Staged Metaprogramming for Shader System Development
Kerry A. Seitz, JR.,
T. Foley,
Serban D. Porumbescu,
John D. Owens
ACM SIGGRAPH Asia 2019
The shader system for a modern game engine comprises much more than just compilation of source code to executable kernels. Shaders must also be exposed to art tools, interfaced with engine code, and specialized for performance. Engines typically address each of these tasks in an ad hoc fashion, without a unifying abstraction. The alternative of developing a more powerful compiler framework is prohibitive for most engines.
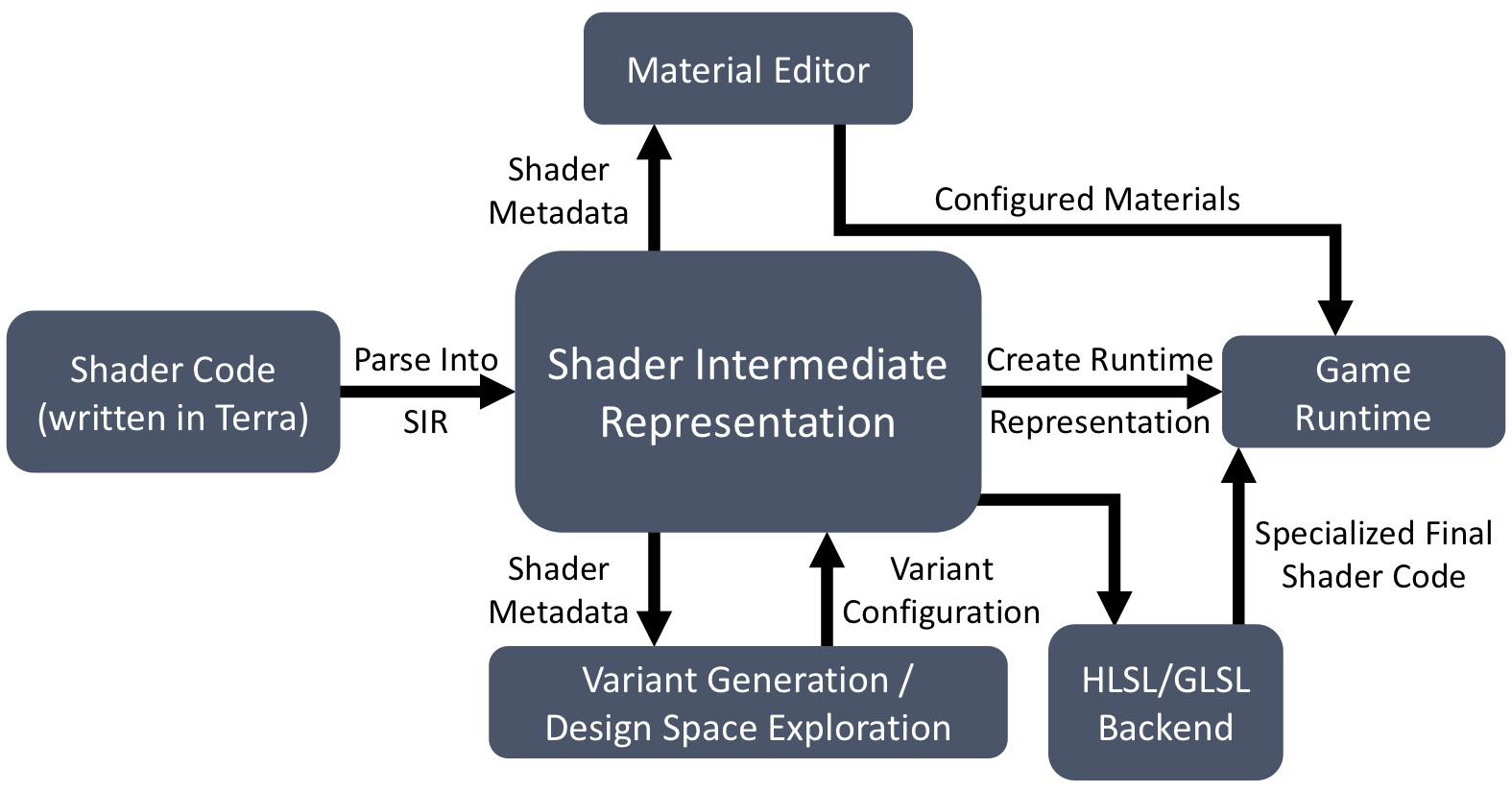
In this paper, we identify staged metaprogramming as a unifying abstraction and implementation strategy to develop a powerful shader system with modest effort. By using a multi-stage language to perform metaprogramming at compile time, engine-specific code can consume, analyze, transform, and generate shader code that will execute at runtime. Staged metaprogramming reduces the effort required to implement a shader system that provides earlier error detection, avoids repeat declarations of shader parameters, and explores opportunities to improve performance.
To demonstrate the value of this approach, we design and implement a shader system, called Selos, built using staged metaprogramming. In our system, shader and application code are written in the same language and can share types and functions. We implement a design space exploration frame- work for Selos that investigates static versus dynamic composition of shader features, exploring the impact of shader specialization in a deferred renderer. Staged metaprogramming allows Selos to provide compelling features with a simple implementation.
Anders Brodersen,
Ken Museth,
Serban Porumbescu,
Brian Budge
IEEE Transactions on Visualization and Computer Graphics 2008
We present techniques for warping and blending (or
subtracting) geometric textures onto surfaces represented by high
resolution level sets. The geometric texture itself can be
represented either explicitly as a polygonal mesh or implicitly as a
level set. Unlike previous approaches, we can produce topologically
connected surfaces with smooth blending and low distortion.
Specifically, we offer two different solutions to the problem of
adding fine-scale geometric detail to surfaces. Both solutions
assume a level set representation of the base surface which is
easily achieved by means of a mesh-to-level-set scan conversion. To
facilitate our mapping, we parameterize the embedding space of the
base level set surface using fast particle advection. We can then
warp explicit texture meshes onto this surface at nearly interactive
speeds or blend level set representations of the texture to produce
high-quality surfaces with smooth transitions.
A shell map is a bijective mapping between shell space and texture space that can be used to generate small-scale features on surfaces using a variety of modeling techniques. The method is based upon the generation of an offset surface and the construction of a tetrahedral mesh that fills the space between the base surface and its offset. By identifying a corresponding tetrahedral mesh in texture space, the shell map can be implemented through a straightforward barycentric-coordinate map between corresponding tetrahedra. The generality of shell maps allows texture space to contain geometric objects, procedural volume textures, scalar fields, or other shell-mapped objects.
Meshless Isosurface
Generation from Multiblock Data
Christopher S. Co, Serban D.
Porumbescu, Kenneth I. Joy
VisSym 2004
We propose a meshless method
for the extraction of high-quality continuous isosurfaces from
volumetric data represented by multiple grids, also called multiblock
data sets. Multiblock data sets are commonplace in computational
mechanics applications. Relatively little research has been performed
on contouring multiblock data sets, particularly when the grids overlap
one another. Our algorithm proceeds in two steps. In the first step, we
determine a continuous interpolant using a set of locally defined
radial basis functions (RBFs) in conjunction with a partition of unity
method to blend smoothly between these functions. In the second step,
we extract isosurface geometry by sampling points on Marching Cubes
triangles and projecting these point samples onto the isosurface
defined by our interpolant. A surface splatting algorithm is employed
for visualizing the resulting point set representing the isosurface.
Because of our method's generality, it inherently solves the crack
problem in isosurface generation. Results using a set of synthetic data
sets and a discussion of practical considerations are presented. The
importance of our method is that it can be applied to arbitrary grid
data regardless of mesh layout or orientation.
Dataflow and Remapping for Wavelet Compression and View-dependent Optimization of Billion-Trangle Isosurfaces
Mark A. Duchaineau, Serban D. Porumbescu, Martin Bertram, Bernd Hamann, Kenneth I. Joy
in G. Farin, H. Hagen, and B. Hamann, eds., Approximation and Geometrical Methods for Scientific Visualization, Springer-Verlag, Heidelberg, Germany, 2003, 10 pages.
Currently, large physics simulations produce 3D discretized field data whose individual isosurfaces, after conventional extraction processes, contain upwards of hundreds of millions of triangles. Detailed interactive viewing of these surfaces requires (a) powerful compression to minimize storage, and (b) fast view-dependent optimization of display triangulations to most efectively utilize high-performance graphics hardware. In this work, we introduce the first end-to-end multiresolution data flow strategy that can effectively combine the top performing subdivision-surface wavelet compression and view-dependent optimization methods, thus increasing efficiency by several orders of magnitude over conventional processing pipelines. In addition to the general development and analysis of the data flow, we present new algorithms at two steps in the pipeline that provide the "glue" that makes an integrated large-scale data visualization approach possible. A shrink-wrapping step converts highly detailed unstructured surfaces of arbitrary topology to the semi-structured meshes needed for wavelet compression. Remapping to triangle bintrees minimizes disturbing "pops" during realtime display-triangulation optimization and provides effective selective-transmission compression for out-of-core and remote access to extremely large surfaces. Overall, this is the first effort to exploit semi-structured surface representations for a complete large-data visualization pipeline.
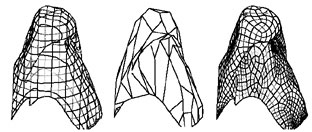
Automatic Semi-Regular Mesh Construction from Adaptive Distance Fields
Peer Timo Bremer, Serban D. Porumbescu, Bernd Hamann, Kenneth I. Joy
Curve and Surface Fitting: Saint-Malo 2002
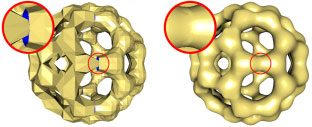
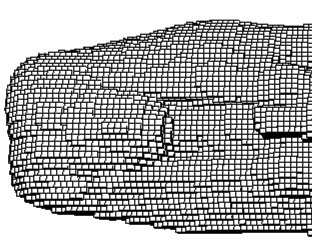
This paper describes a method to construct semi-regular meshes for a surface S defined by the zero set of a trivariate function F(x,y,z), representing a distance field definition of S. An adaptive distance field (ADF) definition of S is obtained by constructing, adaptively, an octree decomposition of F's domain. The vertices of the octree-based definition of S lie either on the positive or negative side of S (or on S). Octree cells that are intersected by S are identified, and the faces of these cells that lie on the outside of S are projected onto S. The result is a quadrilateral mesh to which various procedures are applied that lead to an improved mesh containing a much smaller number of extraordinary vertices, i.e., non-valence-four vertices.
Virtual Clay Modeling Using Adaptive Distance Fields
Peer Timo Bremer, Serban D. Porumbescu, Falko Kuester, Bernd Hamann, Kenneth I. Joy, Kwan-Liu Ma
in H. R. Arambnia et al., eds., Proceedings of the 2002 International Conference on Imaging Science, Systems, and Technology (CISST 2002), Volume 1, Computer Science Research, Education, and Applications Press, Athens, Georgia, 2002.
This paper describes an approach for the parametrization and modeling of objects represented by adaptive distance fields (ADFs). ADFs support the construction of powerful solid modeling tools. They can represent surfaces of arbitrary and even changing topology, while providing a more intuitive user interface than control-point based structures such as B-splines. Using the octree structure, an adaptively refined quadrilateral mesh is constructed that is topologically equivalent to the surface. The mesh is then projected onto the surface using multiple projection and smoothing steps. The resulting mesh serves as the ``interface'' for interactive modeling operations and high-quality rendering.
Interactive Display of Surfaces Using Subdivision Surfaces and Wavelets
Duchaineau, M.A., Bertram, M., Porumbescu, S., Hamann, B. and Joy, K.I.
in Kunii, T.L. ed., Proceedings of Spring Conference on Computer Graphics 2001, Comenius University, Bratislava, Slovak Republic, pp. 22--34.
Complex surfaces and solids are produced by large-scale modeling and simulation activities in a variety of disciplines. Productive interaction with these simulations requires that these surfaces or solids be viewable at interactive rates � yet many of these surfaces/solids can contain hundreds of millions of polygons/polyhedra. Interactive display of these objects requires compression techniques to minimize storage, and fast view-dependent triangulation techniques to drive the graphics hardware. In this paper, we review recent advances in subdivision-surface wavelet compression and optimization that can be used to provide a framework for both compression and triangulation. These techniques can be used to produce suitable approximations of complex surfaces of arbitrary topology, and can be used to determine suitable triangulations for display. The techniques can be used in a variety of applications in computer graphics, computer animation and visualization.