Setareh Rafatirad
Associate Professor
Computer Science Department
Mail: s r a f a t i r a d @ u c d a v i s . e d u
Research
I have broad research interests in Applied Machine Learning, Natural Language Processing, Open-AI, Semantic Computing ,IoT Security, AI for Health, and AI-Assisted Education Equity. Some of the past and present projects are listed in this page.
Gender and Racial Equity in Education
Data Science has recently experienced a significant surge in producing undergraduate degree/certificate and course enrollments. This growth has resulted in straining program resources at many institutions and causing concern about how to most effectively respond to the rapidly growing demand and provide equal opportunities for all students to pursue their degree. The primary goal of this work is to provide an intelligent solution to automatically identify biases related to race and gender in the content of Data Science related courses such as Machine Learning (ML), Natural Language Processing (NLP), Data Mining, Data Analytics, and Knowledge Discovery just to name a few. While machine learning allows to build powerful predicting tools, it hasn’t been used sufficiently to detect biases rooted in gender and race in educational material.
Hence, using effective machine learning techniques we aim to enhance the success rate of undergraduate students in Data Science education and programs while promoting engagement through identifying and mitigating potential gender and racial biases. To this end, we propose a novel bias detection approach which uses a combination of gender identification and sentiment classification for characterization of gender and race in educational contents. Our proposed framework can help educators and course developers to mitigate race and gender biases in their course materials and create an equitable learning experience for students of minority and under-represented groups.
Computer Vision and Deep Machine Learning Solutions for Malware Detection
Stealthy malware is a malware created by embedding the malware in a benign application through advanced obfuscation strategies to thwart the detection. To perform efficient malware detection for traditional and stealthy malware alike, we propose a two-pronged approach. Firstly, we extract the microarchitectural traces obtained while executing the application, which are fed to the traditional ML classifiers to detect malware spawned as separate thread. In parallel, for an efficient stealthy malware detection, we introduce an automated localized feature extraction technique that will be further processed using the recurrent neural networks (RNNs) for classification. To perform this, we translate the application binaries into images and further convert it into sequences and extract local features for stealthy malware detection.With the proposed two-pronged approach, an accuracy of 94% and nearly 90% is achieved in detecting normal and stealthy malware created through code relocation obfuscation technique. Furthermore, the proposed approach achieves up to 11% higher -
detection accuracy compared to the CNN-based sequence classification and hidden Markov model (HMM) based approaches in detecting stealthy malware.The results of this work has been published in DATE 2019, ICTAI 2019, ICMLA 2019, CASES-ESWEEK 2019 conferences.
Analyzing Hardware Based Malware Detectors
Malware detection at the hardware level is an effective solution to increasing security threats. Hardware based detectors rely on Machine-Learning (ML)classifiers to detect malware-like execution pattern based on Hardware Performance Counters(HPC) information at run-time. The effectiveness of these methods relies on the information provided by expensive-to-implement limited number of HPCs. We analyze various robust ML methods to classify benign and malware applications and effectively improve the classification accuracy by selecting important HPCs. We fully implemented these classier at OS Kernel to understand various software overheads. The software implementation of these classifiers found to be relatively slow.
We propose a hardware-accelerated implementation of these algorithms where the studied classifiers are synthesized to compare various design parameters including logic area, power, and latency. The results show that while ML classier such as MLP are achieving close to 90% accuracy, after taking into consideration their implementation overheads, they perform worst in terms of PDP, accuracy/area and latency compared to simpler but less accurate rule based and tree based classifiers. Results show OneR to be the most cost-effective classier, achieving highest accuracy per logic area, while relying on only branch-instruction HPC information. This work has led to a publication in DAC 2017 conference and a journal in ACM TODAES.
Memory Navigation for Modern Hardware in a Scale-out Environment
Scale-out infrastructure such as Cloud is built upon a large network of multi-core processors. Performance, power consumption, and capital cost of such infrastructure depend on the overall system configuration including number of processing cores, core frequency, memory hierarchy and capacity, number of memory channels, and memory data rate. Among these parameters, memory subsystem is known to be one of the performance bottlenecks, contributing significantly to the overall capital and operational cost of the server. Also, given the rise of Big Data and analytics applications, this could potentially pose an even bigger challenge to the performance of cloud applications and cost of cloud infrastructure. Hence it is important to understand the role of memory subsystem in cloud infrastructure. Currently there is no well-defined methodology for selecting a memory configuration that reduces execution time and power consumption by considering the capital and operational cost of cloud.
In this work, through a comprehensive real-system empirical analysis of performance, we address these challenges by first characterizing diverse types of scale-out applications across a wide range of memory configuration parameters. The characterization helps to accurately capture applications’ behavior and derive a model to predict their performance. We propose MeNa, which is a methodology to maximize the performance/cost ratio of scale-out applications running in cloud environment. MeNa navigates memory and processor parameters to find the system configuration for a given application and a given budget, to maximum performance. Compared to brute force method, MeNa achieves more than 90% accuracy for identifying the right configuration parameters to maximize performance/cost ratio. This work has led to a conference publication in IEEE IISWC 2017.
Big Data Analytics for Constructing Domain Event-Ontologies
The advent of technology and abundance of sensors on handheld devices has led to the proliferation of open source datasets with sensory metadata (like time, location, so forth). Cloud-based off-the-shelf computer vision APIs like Project Oxford and Clarifai are abundantly becoming available to report high-level metadata concepts from the images pixel values. The availability of semantic web technology as defacto standard to create structured metadata and ontologies for a domain of interest, linked-data sources (like Google knowledge graph and Wikipedia) -providing background knowledge, big data analytics and deep learning algorithms,
and various web services and public database APIs, combined, provides semantic richness which should be leveraged to infer high-level semantics and bridge the semantic gap. The goal of this project is integrating the metadata from personal photo streams with information provided by various contextual data sources, APIs, tools, and techniques to model spatio-temporal entities,called events, and construct event-based domain ontologies, which later leads to detecting daily activities and events, and discovering correlations among them. Such outcome can be used in variety of applications including multimedia information retrieval, information organization, and healthcare.
Housing Analytics
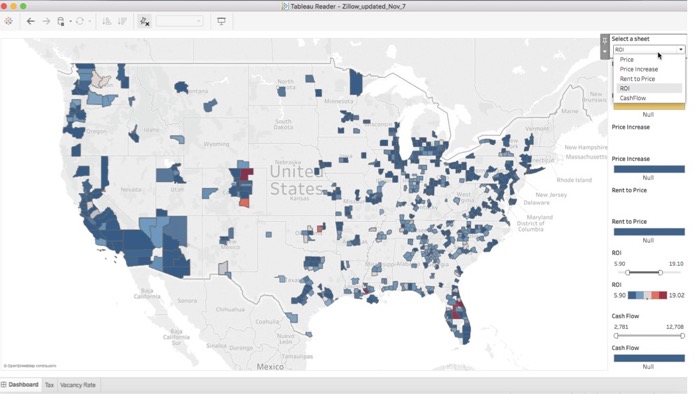
Big data is transforming several domains, including real-estate industry. Real-estate companies like Zillow, Redfin, and Realtor offer applications utilized by expert/ordinary users. However, these applications lack the necessary components for providing a personalized analytical framework to meet the individual need to explore and choose the best investment options. The goal of this project is to address this problem. In our research group, a team of students are currently developing the code and software to collect, analyze, and visualize housing data and environmental factors for the U.S. regions. We are exploring a variety of Machine Learning and Deep Learning techniques for housing price prediction, and improve the accuracy of the results. In this project, we aim to improve the accuracy of our prediction algorithm.
We have tested several traditional ML algorithms on our data. We will examine Ensemble Learning (such as Random Forest) and Deep Learning techniques (such as CNN) as the size of data grows. In addition, we have collected historic data for all US states which we are using to develop time-series rent prediction model. However, with growing size of data, we are facing several challenges including high frequency of missing data. We will investigate an array of imputation techniques to avoid from a biased training set, and therefore, end up with higher model accuracy. In addition, we are investigating many external parameters that could influence the prediction models related to urban development. Another goal of this ongoing project is creating a mobile app software for both Android and iOS devices, so that system users can visually and empirically interact with the results of our research findings.